
Ce sujet est composé de deux articles (hors introduction) : une exploration théorique de ce qu’est un type de données répliquées convergent et commutatif. Cette première partie définit les propriétés mathématiques que doivent respecter ces types de données.
La seconde partie de l’article est un portfolio d’exemples pratiques.
Partie 1 : Modèle théorique
TL;DR
Partons du principe que le réseau distribue à la longue les opérations de mises à jour entre tous les nœuds. Les nœuds sont de confiance et peuvent être déconnectés et reconnectés. Les nœuds continuent à opérer pendant les instants de déconnexion.
Plusieurs contraintes sur les opérations possibles sur les objet de ces nœuds garantissent la cohérence à terme des répliques de cet objet partagé sans synchronisation, ni consensus, à priori.
En basant le type de données sur l’état, ces contraintes sont :
- Associativité :
fusion(x, fusion(y,z)) = fusion(fusion(x,y), z) - Commutativité :
fusion(x,y) = fusion(y,x) - Idempotence :
fusion(x,x) = x
En basant le type de données sur l’opération, ces contraintes sont :
- Associativité :
op(x, op(y,z)) = op(op(x,y), z) - Commutativité :
op(x,y) = op(y,x)
Introduction
La situation d’exercice est composée de processus reliés entre eux par un réseau asynchrone. Le réseau peut se partitionner (certains nœuds se retrouvent déconnectés) et récupérer (les nœuds déconnectés se reconnectent), et les nœuds peuvent opérer lors d’une déconnexion. Tous les nœuds sont de confiance (non-byzantin). Le fait de garantir la cohérence à terme requiert qu’à la longue, le réseau distribue toutes les mises à jour pour toutes les répliques.
Atomes et Objets
Un atome est un invariant représenté par sa valeur. Par exemple « 123 », « 3,14 », ou « sérendipité ». Un objet est une donnée répliquée et mutable, composée d’atomes et/ou d’objets. Un objet possède une interface composée d’opérations. Deux objets possédant la même identité mais située dans des processus différents sont appelés répliques. Les répliques sont indépendantes et l’on peut se concentrer sur une réplique à la fois.
Opérations
Des clients non spécifiés peuvent questionner et modifier l’état d’un objet en appelant des opérations de son interface. Les questions sont exécutées localement au niveau de la réplique. Une révision/modification a lieu en deux parties : la réplique se modifie, puis transmet la modification de manière asynchrone à toutes les répliques. C’est la partie en aval (downstream).
Réplication basée sur l’état
Lors d’une réplication basée sur l’état, ou passive, la modification a entièrement lieu localement, puis la totalité de l’objet est envoyé aux répliques. La vivacité est assurée par le réseau qui à la longue transmettra tous les nouveaux états.
L’histoire causale C se définit de manière récursive.
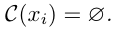 À l’état initial, l’histoire causale d’une réplique est vide.
À l’état initial, l’histoire causale d’une réplique est vide. 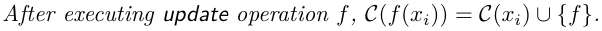 À chaque opération, on rajoute l’opération à l’histoire causale de la réplique.
À chaque opération, on rajoute l’opération à l’histoire causale de la réplique.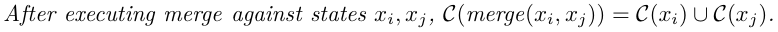 Exécuter une fusion de deux états modifie l’histoire causale tel que « l’histoire causale de la fusion » est équivalent à « l’union des histoires causales »
Exécuter une fusion de deux états modifie l’histoire causale tel que « l’histoire causale de la fusion » est équivalent à « l’union des histoires causales »- Bonus :
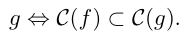 La relation a-lieu-avant peut se représenter en histoires causales. Si
La relation a-lieu-avant peut se représenter en histoires causales. Si fa-lieu-avantg, alors l’histoire causale defsera incluse dans l’histoire causale deg
Réplication basée sur l’opération
Dans une réplication basée sur les opérations, ou active, la modification a entièrement lieu localement, puis la partie en aval est envoyée aux répliques pour être exécutée.
La vivacité est assurée par le réseau qui à la longue transmettra toutes les mises à jour dans un ordre suffisant pour assurer l’histoire causale. Il n’est pas nécessaire de délivrer les mises à jour dans l’ordre tant que l’ordre effectif de livraison est suffisant pour assurer l’histoire causale.
Convergence
- Sûreté : Pour toute réplique, si deux répliques ont la même histoire causale alors leur états abstraits sont équivalents.
- Vivacité : À la longue, toutes les mise à jour sont délivrées à toutes les autres répliques.
- Bonus : Deux répliques sont équivalentes si elles retournent les mêmes valeurs pour chaque questionnement.
Types de données répliqués convergentes (CvRDT)
Définition : Plus petite limite supérieure
La plus petite limite supérieure (Least Upper Bound, ou LUB) est facilement explicable en prenant comme exemple son application aux nombres réels.
«Pour un set S non vide de nombres réels :
- Un réel x est la limite supérieur de S si et seulement si x est plus grand que chacun des éléments de S.
- Le réel y est la plus petite limite supérieure* de S si et seulement si **y est le plus petit des limites supérieurs de S. »
Ainsi, la plus petite limite supérieure (Least Upper Bound, ou LUB) de n’importe quel set d’un ensemble partiellement ordonné X est la définition précédente du LUB dont on a remplacé «nombres réels» par «élément de X».
Définition : Join Semilattice
Un Join Semilattice est un Set ordonné où, pour tous les éléments x et y appartenant au Set, LUB(x,y) existe.
Ainsi, LUB a les propriété suivantes :
- Associativité :
LUB(x, LUB(y,z)) = LUB(LUB(x,y), z) - Commutativité :
LUB(x,y) = LUB(y,x) - Idempotence :
LUB(x,x) = x
Propriétés des types de données répliquées convergentes (CvRDT)
Un type de données répliqués convergents produit des objets basés sur l’état dont les valeurs appartiennent à un Join Semilattice, et dont les opérations de mise à jour convergent vers le LUB des valeurs initiales et mises à jour. De plus, les mises à jour successives convergent vers le LUB de toutes les récentes valeurs.
Par définition, si deux répliques d’un CvRDT se communiquent la totalité de leur mises à jour, leur états convergent.
Types de données répliquées commutatives (CmRDT)
Les opérations d’un objet qui peuvent ne pas être livrées dans l’ordre d’exécution sont dites concurrentes. Si toutes les opérations concurrentes commutent, alors tous les ordres de livraisons sont équivalents et toutes les répliques convergent vers le même état.
Un objet basé sur les opérations, et dont toutes les opérations sont concurrentes est un type de donnée répliqué commutatif.
Pour se faire, il faut que les opérations soient applicables à l’objet dans toutes les situations. De plus, pour deux opérations f et g agissant sur l’état E de l’objet x, ces opérations doivent être commutables : E = f(g(x)) = g(f(x)).
La suite dans la Partie 2 : Exemples pratiques ^^
Photo : I’m getting wet – Kristina Alexanderson
Légende : Cette photo fait référence à l’exemple de la partie 2 concernant le système distribué de mesure de la pluie. 🙂
Une réflexion au sujet de « Types de données répliquées convergentes et commutatives – Partie 1 : Théorie »
[…] Partie 1 : Théorie […]
Types de données répliquées convergentes et commutatives – Sérendipiteur